Every attack surface management decision eventually comes down to one question that has nothing to do with features: where does your reconnaissance data live? A complete inventory of your exposed assets, the vulnerabilities on each one, and the exploit paths between them is among the most sensitive data your organization produces. Cloud and on-prem ASM both work; they just answer the data-residency question very differently. This guide lays out the trade-off honestly – no fear-mongering – so a regulated team can choose deliberately.
It is the companion to our pillar guide, The Best On-Prem External Attack Surface Management Platform, which covers platform selection. Here we focus on the sovereignty decision itself.
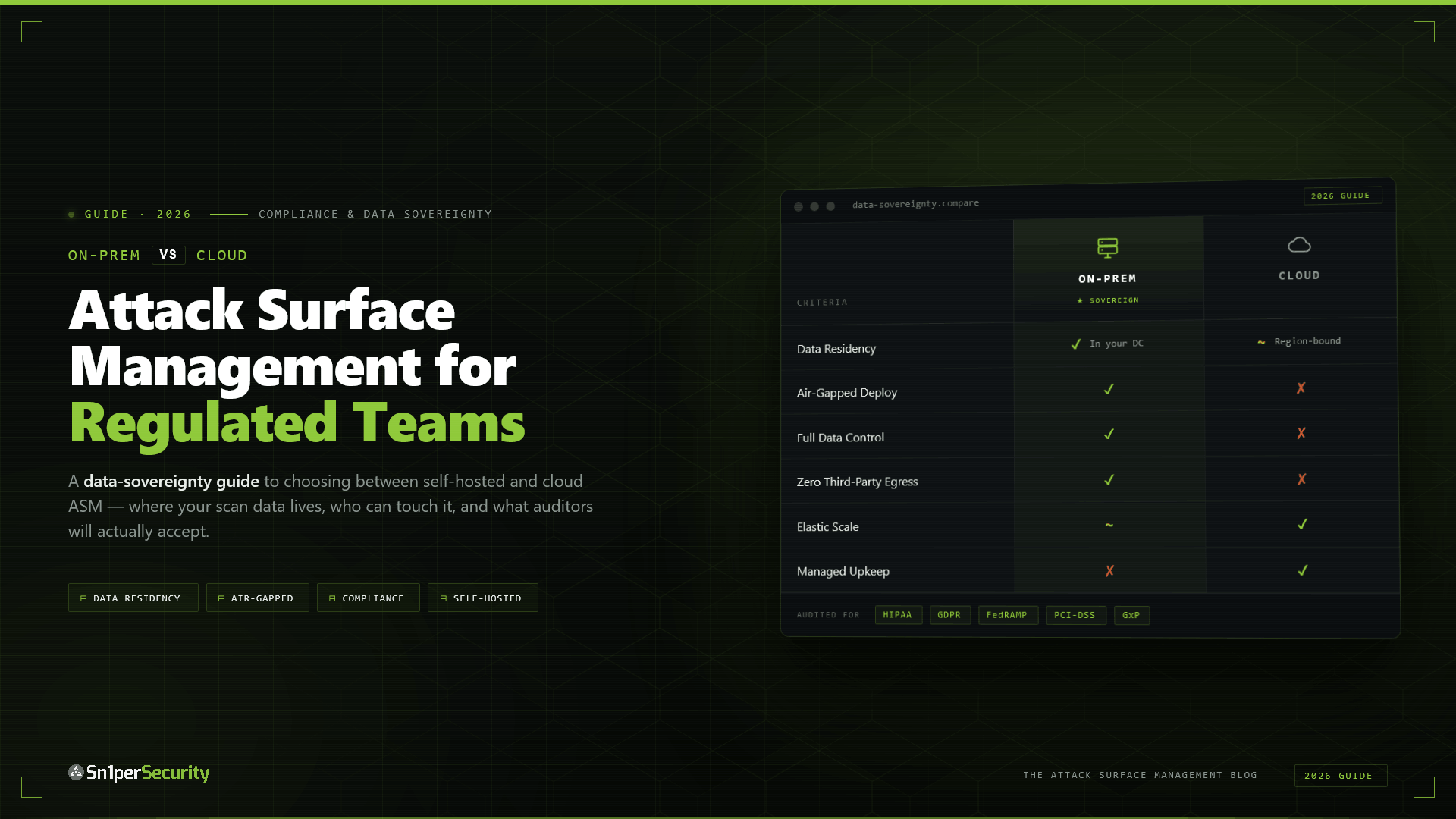
Where your recon data goes in each model
With a cloud (SaaS) ASM platform, your asset inventory and findings are transmitted to and stored on the vendor’s multi-tenant infrastructure. They run the scans (or aggregate from a shared internet-wide graph), they hold the database, and they render the reports. You log into their portal to see your own attack surface.
With an on-prem (self-hosted) ASM platform, the engine, database, UI, and reporting run on infrastructure you control. Findings are written to a database on your host. Nothing about your attack surface leaves your perimeter unless you explicitly export it.
That single architectural difference cascades into legal, compliance, and threat-model consequences that are easy to underweight until an auditor, a regulator, or an incident forces the issue.
Why your attack-surface map is uniquely sensitive
It is worth being precise about what this data is, because attack-surface data is not like other security telemetry. An EASM platform produces a continuously updated, prioritized inventory of every internet-facing asset you own and the specific weaknesses on each one. Read from the wrong side of the table, that is an attacker’s pre-built roadmap: the forgotten staging host, the expired certificate, the unpatched service, the login portal with no rate limiting – ranked by exploitability, with the easy wins at the top.
Most security data describes attacks that already happened. Attack-surface data describes the attacks that could happen, before anyone has tried. That asymmetry is what makes it valuable to a defender and dangerous in the wrong hands. When that inventory lives in a multi-tenant SaaS backend, you are trusting the vendor not only with confidentiality but with the most useful single document an adversary could obtain about your organization. For many teams that is reason enough to keep it in-house, independent of how good the vendor’s own security is.
The SaaS data-processing relationship you inherit
The moment a cloud ASM vendor stores data that can identify systems and, by extension, people, GDPR treats them as a data processor and you as the controller. Under Article 28 that means a Data Processing Agreement to negotiate and maintain, ongoing processor due diligence, a documented sub-processor chain to audit, and a breach-notification dependency: if the vendor is breached, your ability to meet your own Article 33 72-hour notification deadline depends on their incident-response timeline.
Self-hosting collapses that relationship. Run the platform yourself and you are both controller and sole processor: no DPA, no sub-processor audit, no third-party breach clock in your critical path. For organizations that already carry heavy compliance load, removing an entire processor relationship is a material simplification, not a marginal one.
Jurisdiction and cross-border transfer
Even a perfectly run SaaS vendor cannot opt out of its own jurisdiction. The US CLOUD Act allows US authorities to compel data held by US-headquartered providers regardless of where the servers sit. Sending EU personal data to non-EU infrastructure requires Standard Contractual Clauses or another approved transfer mechanism. For some data classes and some risk tolerances, that math only resolves one way: the data does not cross the boundary, which in practice means a deployment with no data leaving your jurisdiction at all.
The regulatory backdrop has hardened in 2026. The EU AI Act reached its main application date on 2 August 2026, carrying penalties up to 7% of global annual turnover; sector frameworks like DORA in financial services push the same direction. Where AI is part of the security workflow, “sovereign” now spans three layers that all have to stay inside one legal perimeter: the data layer (prompts, findings, logs), the control layer (keys, model endpoints, orchestration), and the legal layer (which jurisdiction binds you).
Your offensive-AI model should never leave your perimeter
AI has quietly become the part of the security stack most likely to leak. The instant a tool sends a request, a finding, or a snippet of your code to a hosted LLM API, that data is in someone else’s system – possibly logged, possibly retained, definitely outside your control. For offensive tooling, where the “prompt” is often a live vulnerability or a piece of a target system, that is a meaningful exposure.
The fix is the same principle applied to AI: keep inference in-perimeter. SILENTCHAIN AI Community Edition is a free Burp Suite extension that analyzes HTTP traffic for OWASP Top 10 issues and supports a local Ollama runtime, so the model runs on your machine and prompts never touch a third-party API. Run it alongside a self-hosted Sn1per deployment and the entire offensive workflow – discovery, scanning, and AI-assisted analysis – stays inside the boundary you control.
The honest tension: cloud intelligence vs. local control
It would be dishonest to pretend self-hosting has no trade-offs. Classic external ASM derives much of its breadth from a vendor-maintained, internet-wide intelligence graph – passive DNS, certificate transparency at scale, historical scan data across millions of hosts. That shared graph is, by definition, a cloud asset. A fully self-hosted platform gives that up in exchange for control.
In practice the gap is smaller than it sounds, because a self-hosted platform does its own active and passive reconnaissance from your egress rather than querying a borrowed graph. Sn1per orchestrates 90+ reconnaissance and scanning tools to discover subdomains, enumerate ports and services, fingerprint technologies, and test for vulnerabilities directly. You trade a vendor’s historical breadth for live, first-party data that never leaves your control – usually the right trade when residency is the constraint, and a poor one when you genuinely need internet-scale historical correlation. Name the constraint first, then choose.
Compliance posture by deployment model
| Requirement | Cloud / SaaS ASM | Self-hosted (on-prem) | Air-gapped |
|---|---|---|---|
| SOC 2 / ISO 27001 commercial baseline | Sufficient | Sufficient | Sufficient |
| GDPR / HIPAA data residency | Needs DPA + SCCs | Satisfied (you are controller + processor) | Satisfied |
| No third-party processor in breach chain | No | Yes | Yes |
| Defense / classified / sovereign | No | Often | Yes |
| Operates with no internet connectivity | No | Yes | Yes |
| Operational overhead | Lowest (vendor-managed) | Moderate (you patch and run it) | Highest |
When cloud ASM is the right call
Self-hosting is not a moral position, and SaaS is not disqualified. A cloud ASM platform with SOC 2 Type II, ISO 27001, and a well-structured DPA that pins data residency is a reasonable choice for teams with limited infrastructure capacity, low regulatory exposure, and findings that would not cause serious harm if exposed. The deciding factors are consistent: the sensitivity of the data, the jurisdictions in play, your tolerance for a third-party processor relationship, and whether you need internet-scale historical intelligence. If none of those bite, the lower operational overhead of SaaS is a legitimate win.
The goal is not to self-host everything. It is to ensure that data subject to regulatory scrutiny – and a full map of your attack surface usually qualifies – lives on infrastructure you control.
The operational reality of self-hosting in 2026
The classic argument against self-hosting was operational overhead: someone has to patch the box, update the tooling, and run the scans. That objection has weakened considerably. Container-first deployment turns a multi-day install into a single docker compose up, and the infrastructure to run a self-hosted scanner is modest – a single VM or a spare server, not a rack. Measured against the average breach cost or the penalty schedule of a regulation like the EU AI Act, the marginal infrastructure spend is a rounding error.
That does not make the overhead zero, and pretending otherwise would be dishonest. With self-hosting you own three things you previously outsourced: patching (you decide when to apply updates – a feature for change-controlled environments, a chore everywhere else), monitoring (the platform’s own uptime is now yours to watch), and scan execution (no vendor cron runs in the background; you schedule it). The upside is that all three are now under your control rather than a vendor’s, which is precisely the point for regulated and air-gapped work. The honest framing is not “self-host everything to save money” – it rarely saves money outright – but “self-host the data that cannot leave, and treat the operational cost as the price of sovereignty.”
Running ASM entirely in your perimeter
If the sovereignty decision points to self-hosting, the operational path is straightforward. A Docker-first platform stands up in minutes and runs with no outbound dependency at scan time:
# Self-hosted ASM platform, data persisted to your PostgreSQL on your host
docker compose up -d sn1per-pro
# Scan a client surface into a named workspace - findings stay local
sniper -t client-acme.com -m web -w acme
For isolated networks, the same image exports across an air gap with no registry or license phone-home:
docker save sn1per-pro-2026:latest -o sn1per-pro-2026.tar
# carry across the gap, then:
docker load -i sn1per-pro-2026.tar
docker compose up -d sn1per-pro
From there, the documentation covers scheduled scans, exportable reports, and the JSON API so findings flow into your SIEM rather than a vendor portal.
A decision framework
Strip away the marketing and the choice comes down to a short list of questions. Answer them honestly and the right deployment model usually picks itself:
- How is the data classified? If your attack-surface inventory would be classified confidential or higher, that points to self-hosted or air-gapped.
- What jurisdiction binds you? If a non-domestic SaaS vendor would create cross-border-transfer or CLOUD Act exposure you cannot paper over, the data should not leave your jurisdiction.
- Which regulations apply? GDPR, HIPAA, DORA, and defense frameworks raise the bar; SOC 2 and ISO 27001 commercial baselines do not, on their own, require self-hosting.
- Do you have the capacity to run it? A container and a scheduled scan is a low bar, but it is not zero. If you genuinely cannot, a well-papered SaaS may be the pragmatic choice.
- Do you need internet-scale historical intelligence? If your use case depends on a vendor’s global graph for broad third-party or supply-chain discovery, that is the one capability self-hosting trades away.
- Is AI in the loop? If so, decide where inference runs. Local-model support keeps prompts and findings in-perimeter; a hosted LLM API does not.
If most answers lean toward sensitivity, jurisdiction, and regulation, self-host. If they lean toward convenience and breadth at low data sensitivity, SaaS is defensible. The mistake is not picking either model – it is picking by default, without naming the constraint.
Bottom line
Cloud ASM optimizes for convenience and internet-scale intelligence at the cost of handing your attack-surface data to a third party. On-prem ASM optimizes for control, residency, and a clean compliance posture at the cost of running it yourself. Decide which constraint is real for your organization, then choose the architecture that matches – and if the answer is on-prem, our on-prem EASM platform guide covers what to deploy.
Frequently asked questions
Is on-prem or cloud attack surface management more secure?
Neither is categorically more secure, but on-prem keeps your attack-surface data inside your perimeter and removes the third-party processor from your breach-notification chain. Cloud offers lower operational overhead and richer shared intelligence. The right choice depends on data sensitivity, jurisdiction, and regulatory exposure.
Does using a SaaS ASM tool create GDPR obligations?
Yes. A SaaS vendor that stores your asset and findings data is a data processor under GDPR Article 28, which requires a Data Processing Agreement, sub-processor due diligence, and a breach-notification dependency. Self-hosting removes that relationship because you are both controller and processor.
Can I keep AI analysis on-premises?
Yes. SILENTCHAIN AI Community Edition supports a local Ollama model runtime, so AI inference runs on your machine and prompts never reach a third-party LLM API. Paired with a self-hosted Sn1per deployment, the whole offensive-security workflow stays in your perimeter.
What is the downside of self-hosted ASM?
You take on operational overhead – patching, updates, and running the scans yourself – and you give up a vendor’s internet-wide historical intelligence graph. A self-hosted platform compensates by performing its own active and passive reconnaissance from your egress, producing live first-party data that never leaves your control.